Videos
You can watch a short video about the project’s results on this link.
Models & Tools
We implemented and trained three machine learning models. One that can detect Bulgarian texts, generated by the GPT-2 and ChatGPT language models, one for detecting disinformation, and one for detecting untrue information. All three models are trained with data in Bulgarian language.
We also created a tool that uses the three models. The tool has three versions. All three versions use the same model for disinformation detection, but different models for textual deepfakes detection, and the last version contains a model for detecting untrue information.
Current release:
TRACES-tool v1.2 : The deepfake model can detect texts generated with the models GPT-2 and ChatGPT, disinformation and untrue information. If a text is recognized as both generated by the language models and containing untrue information or disinformation, it can be considered as potentially being a textual deepfake. The model for detecting untrue information has F1-Score of 0.96.
Previous releases:
TRACES-tool v1.1 : The deepfake model can detect texts generated with the models GPT-2 and ChatGPT, and disinformation. We used 10-fold cross-validation and achieved F1-Score of 0.88.
TRACES-tool v1.0 : The deepfake model can detect texts, generated by GPT-2 with F1-Score 0.9339.
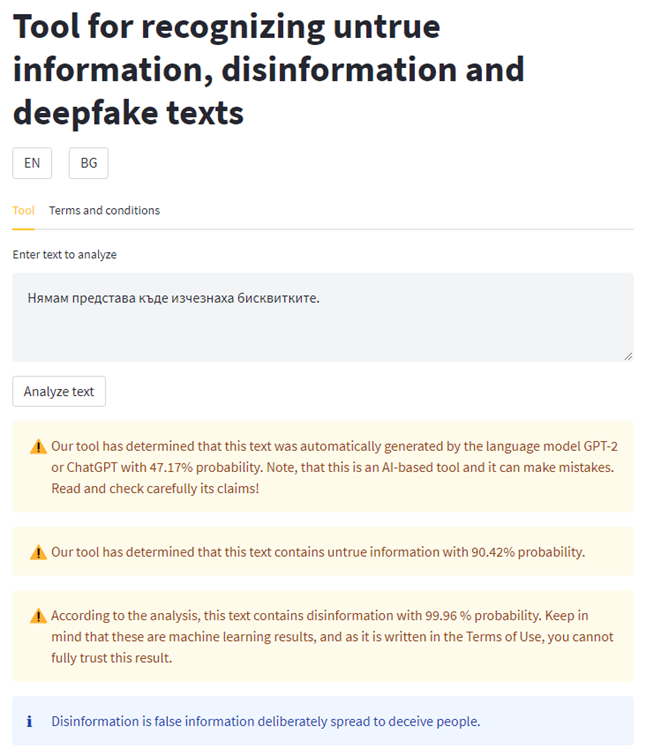
To test the tool, please follow the link to the DEMO. See the screenshot of the tool, containing the input text in Bulgarian with the following translation into English: “I have no idea where did the cookies disappear”.
Note: Тhe code of the tool contains an unpublished third party model for detecting disinformation that will be released it in the next few months. Because of this reason, the tool cannot be yet publicly released, but it is available for testing.
We have publicly released two machine learning models (the ML models with the highest F1-Scores):
- Machine learning model for identifying Bulgarian texts, automatically generated by the language models GPT-2 and ChatGPT, achieving F1-Score 0.88. Can be accessed under legal restrictions on Zenodo.
- Machine learning model for identifying Bulgarian texts, potentially containing untrue information, achieving F1-Score 0.96. The model can be accessed under strict legal conditions on Zenodo.
Datasets
Bulgarian Twitter dataset on Covid-19, annotated with linguistic markers of lies
Bulgarian Telegram dataset, annotated with linguistic markers of lies
Bulgarian Twitter dataset on lies and manipulation, annotated with linguistic markers of lies
Bulgarian sentiment analysis Twitter dataset
Deliverables
Data Management Plan:

The Data Management Plan can be downloaded here.
Annotation Guidelines:
Manual annotation guidelines for journalists for annotating texts with categories “true/untrue” and “disinformation/no disinformation”. The guidelines contain also instructions on how to use an annotation tool.
Bulgarian version of the guidelines:
TRACES_Dts10_Manual_Annotation_Guidelines_for_Journalists_BG_1.0English version of the guidelines (with Bulgarian examples):
TRACES_Dts10_Manual_Annotation_Guidelines_for_Journalists_EN_1.0Research Publications
1 research article accepted at the Language Technologies Conference 2023 (LTC’23):
Irina Temnikova, Silvia Gargova, Ruslana Margova, Veneta Kireva, Ivo Dzhumerov, Tsvetelina Stefanova, and Hristiana Krasteva (2023, Forthcoming). New Bulgarian Resources for Detecting Disinformation. 10th Language & Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics. Poznań, Poland.
1 research article accepted at the conference Computational Linguistics in Bulgaria (CLIB’22):
Silvia Gargova, Irina Temnikova, Ivo Dzhumerov, Hristiana Nikolaeva (September, 2022). Evaluation of Off-the-Shelf Language Identification Tools on Bulgarian Social Media Posts. In Proceedings of Computational Linguistics in Bulgaria (CLIB’22).
The article addresses the lack of updated information about which off-the-shelf language identification tools work the best for Bulgarian social media posts. The paper makes curious discoveries useful as for Bulgarian users, especially those, who have no programming skills; as for researchers of other languages. For more information, read our paper, when uploaded at the conference website, or follow our presentation (in English) online on September 8th or 9th 2022 (there are no fees for participating, but registration is compulsory).
Presentations
Presentation of the project at the AI4Media Open Call 1 funded projects kick-off meeting:
TRACES-Project-Presentation-websiteDissemination events
The project was presented during Institute’s GATE Disinformation (detection) research group Open doors event on January 23, 2023.
The project was presented in Bulgarian during an interactive game/presentation event during European’s scientists night on September 30, 2023.
The project has been advertised at a 2-day educational event on information literacy for librarians in the Bulgarian town of Pazardzhik.
Information about the project has been shared at the International Jubilee Conference Of The Institute For Bulgarian Language 2022, which took place on 15-17 May 2022 in Sofia.
Media articles
A news article in Bulgarian language about the TRACES team working on recognizing deepfake texts appeared on March 10, 2023.
The project members Irina Temnikova and Silvia Gargova were interviewed by 2 Bulgarian radio and 1 tv channel in January 2023.
A news article in Bulgarian language, entirely dedicated to the project TRACES has appeared in an online Bulgarian media outlet.
TRACES has been mentioned in an article at the major Bulgarian daily newspaper 24chasa (in Bulgarian).
TRACES has also been mentioned in an article in the regional Plovdiv daily newspaper Marica (in Bulgarian).
The project has also been mentioned in an article in the Geodesy magazine Geomedia (in Bulgarian).
Information about the project has been shared in a news article on the website of the Regional Library Nikola Furnadzhiev.