Модели и инструменти
Създадохме и тренирахме два модела. Единият за разпознаване на текстови дийпфейкс, а другият за разпознаване на дезинформация. И двата модела са тренирани с данни на български език.
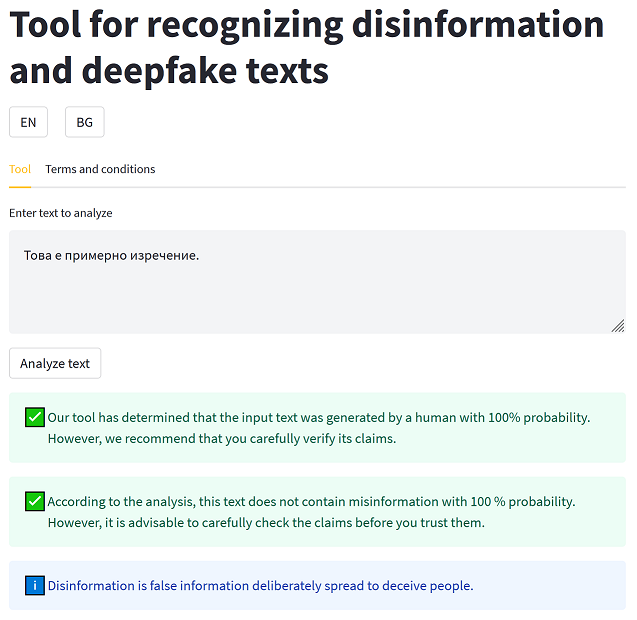
Разработихме и инструмент, който използва двата модела. Инструмента има две версии. И двете версии използват един и същ модел за разпознаване на дезинформация, но различни модели за текстови дийпфейкове.
Актуална версия:
TRACES-tool v1.1: Моделът за текстови дийпфейкове може да разпознава текст написан както от GPT-2, така и от ChatGPT. при тренирането е използвана 10-fold cross-validation и е постигнат F1-Score – 0.88.
Предишни версии:
TRACES-tool v1.0: Моделът за текстови дийпфейкове може да разпознава текст написан от GPT-2, като е постигнат F1-Score – 0.9339.
За да тествате инстумента моля последвайте линка към демото.
Забележка: Кодът на инструмента съдържа непубликуван модел на трета страна, който в момента не е достъпен.
Множества от данни
Събрахме и анотирахме няколко множества от данни, за които може да получите достъп на следните линкове:
Bulgarian Twitter dataset on Covid-19, annotated with linguistic markers of lies
Bulgarian Telegram dataset, annotated with linguistic markers of lies
Bulgarian Twitter dataset on lies and manipulation, annotated with linguistic markers of lies
Bulgarian sentiment analysis Twitter dataset
Събития
Зимен семинар по разпознаване на невярна информация и дезинформация
Проектът TRACES и Институт GATE организират Зимен семинар по разпознаване на невярна информация и дезинформация.
Ако се интересувате от това, как да разпознавате невярната информация и целенасочената заблуда в медиите и в социалните медии, кандидатствайте за иновативния семинар по разпознаване на дезинформацията и измамата! Ако сте начинаещи – ще научите много нова и полезна всестранна информация, а ако имате вече опит, може да научите как да разпознавате фалшивите новини по това, как са написани или изказани, дали съществуват автоматично генерираните текстове (дийпфейкове) на български език, как да ги разпознавате, както и сте добре дошли да споделите знанията си с по-начинаещите.
Събитието е отворено за журналисти и за граждани с активен интерес по темата. В събитието участват установени български специалисти, които ще ви запознаят с полезни инструменти и методи за разпознаване на невярната информация, както и със свързаните с темата юридически аспекти. Участниците ще получат сертификати за участие.
Събитието ще се проведе на 25-ти и 26-ти януари 2023 г. в гр. София в Ректората на Софийския Университет “Св. Климент Охридски” и е с ограничен брой места.
На ограничен брой участници от други населени места в страната ще бъдат покрити разходите за пътуване и 2 нощувки в София.
Теми на събитието:
Кои са основните понятия в областта и как се различава дезинформацията от невярната информация
Как да разпознаем фалшивите новини по езика, на който са написани
Какво са дийпфейковете и съществуват ли в социалните медии на български език
Какви инструменти може да използвате, за да проверявате информацията в уебсайти и в социалните медии
Какви допълнителни мерки за сигурност трябва да взимаме, когато използваме социалните медии
Как да използвате похвати от криминалната лингвистика, за да разпознавате невярната информация
Какви за законите в България и Европейския съюз относно дезинформацията и разкриването на информация (whistleblowers)
За повече информация относно лекторите и съдържанието на Семинара, вижте настоящата версия на програмата:
Програма-на-зимния-семинар-на-проекта-TRACES-версия-26-12-2022План за управление на данните:
AI4Media-OC1-Data-Management-Plan-V3.0Научни публикации
Приета научна статия на 5-тата международна конференция „Компютърна лингвистика в България“ (International Conference Computational Linguistics in Bulgaria, CLIB’22):
Silvia Gargova, Irina Temnikova, Ivo Dzhumerov, Hristiana Nikolaeva (September, 2022). Evaluation of Off-the-Shelf Language Identification Tools on Bulgarian Social Media Posts. In Proceedings of Computational Linguistics in Bulgaria (CLIB’22).
Статията представя сравнение на успеваемостта на най-известните инструменти за автоматично разпознаване на езика, тествани върху текстове от Туитър на български език. Тези инструменти са необходими при сваляне на големи обеми от текстове онлайн, при което често, едновременно с текстовете на български език, се свалят и такива на други подобни езици. Ръчното пресяване на такива постове е изключително трудоемко и понякога дори невъзможно, тъй като става въпрос за големи обеми от данни. Статията допринася с интересни открития относно най-добрия инструмент за такава задача. За повече информация, следвайте презентацията ни онлайн на 8-ми или 9-ти септември 2022 г. (на английски език, няма такси за участие, но регистрацията е задължителна). Можете също така да прочетете статията ни, когато бъде публикувана на уебсайта на конференцията.
Презентации
Събития
Проектът беше представен на двудневното обучение за библиотекари в Регионалната библиотеката в Пазарджик.
Информация за проекта беше представена (и) на Юбилейната международна конференция на Института по български език „Любомир Андрейчин“ през май 2022 г. в София.
Статии в медиите